Nucleic Acid Background
Nucleic acids are the fundamental units of information transfer in biological systems. From bacteria to humans, hereditary information is passed from parent to offspring through deoxyribonucleic acids (DNA). Even viruses—whose status as living or non-living is still up for debate—communicate their replication instructions through DNA or ribonucleic acids (RNA). The structure of the DNA double helix has a famous history and a shape recognizable to people around the world. And while we don’t usually think about the nucleic acids in our food, all living things have it so we consume it all the time!
Nucleic acid building blocks
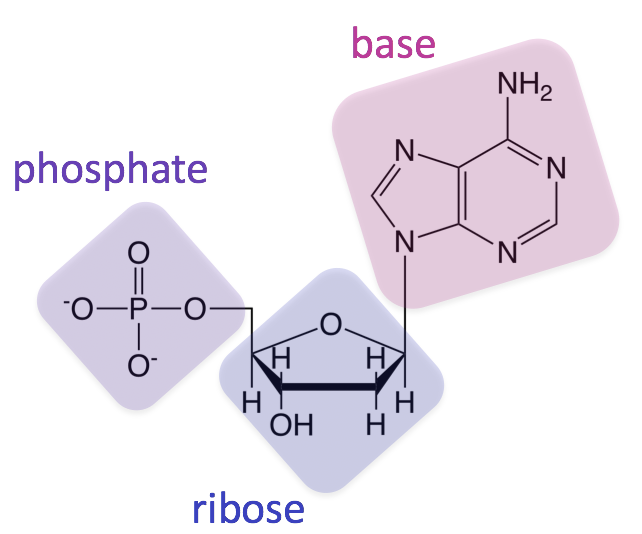 All nucleic acids are comprised of three structural components: a sugar, a phosphate, and a nitrogenous base (a structure containing nitrogen
All nucleic acids are comprised of three structural components: a sugar, a phosphate, and a nitrogenous base (a structure containing nitrogen
). These monomers are called nucleotides. In DNA and RNA, the sugar is a ribose (hence collectively they can be referred to as ribonucleic acids), which is a 5-carbon sugar that forms a pentagon shape (pentose).
Sugars are numbered from the most highly functionalized carbon (so the carbon bonded to both an oxygen and the nitrogenous base in the DNA example above) starting with 1, where these carbons are referred to as 1’ (one prime), 2’ (two prime), etc.
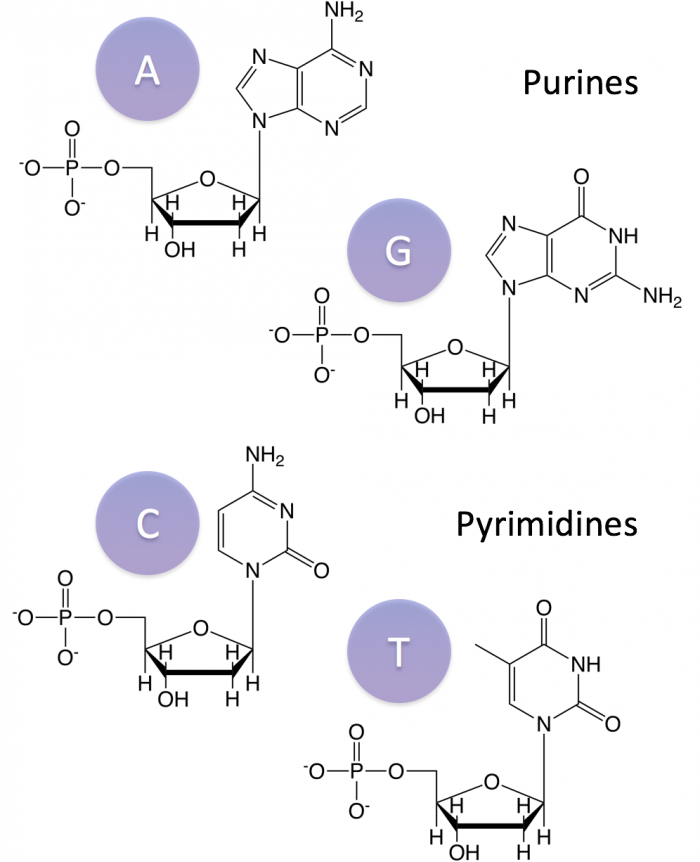
The nitrogenous bases vary. DNA and RNA share three bases: adenine (A), guanine (G), and cytosine (C). The fourth base in DNA is thymine (T) and the fourth base in RNA is uracil (U). Guanine and adenine are purines (named for their double ring structure) while cytosine, thymine, and uracil are pyrimadines (for their single ring structure).
Nucleic acid polymers
In DNA and RNA, the phosphate bonds to the oxygen attached to the 5’ carbon, also known as the 5’ hydroxyl (-OH) within a nucleotide. To form a DNA or RNA polymer, the 5’ phosphate of the incoming monomer forms a bond with the 3’ hydroxyl of the previous nucleotide to form the sugar-phosphate backbone (see the far left or right of the diagram at right). These are dehydration synthesis reactions, similar to the ones performed to make protein polymers from amino acid monomers or starch polymers from sugar monomers.
 DNA exists as two strands aligned antiparallel to one another and connected by many hydrogen bonds between the bases on the opposing strands. It is these highly-specific intermolecular interactions that allow for the ability of DNA to be “read” and “written” based on the complementary interactions. So technically one “DNA molecule” consists of two separate molecules connected only through intermolecular forces. G-C pairs share three hydrogen bonds while A-T/U pairs share only two. Consequently G/C rich regions of DNA are known to be particularly stable (see above).
DNA exists as two strands aligned antiparallel to one another and connected by many hydrogen bonds between the bases on the opposing strands. It is these highly-specific intermolecular interactions that allow for the ability of DNA to be “read” and “written” based on the complementary interactions. So technically one “DNA molecule” consists of two separate molecules connected only through intermolecular forces. G-C pairs share three hydrogen bonds while A-T/U pairs share only two. Consequently G/C rich regions of DNA are known to be particularly stable (see above).
RNA is often simply defined as single-stranded, without question as to the fate of all of the potential hydrogen bonding sites along the bases of the strand. In fact, RNA often folds upon itself to form three-dimensional structures, similar to proteins though rarely as complicated. The most familiar example of this is the structure of a tRNA (at right), where the characteristic cloverleaf shape is formed by hydrogen bonding between bases within the same tRNA molecule. When RNA is not coiled upon itself, it is often bound to other proteins so that these potential hydrogen bonding sites are not exposed.
DNA can melt
Just as melting water involves loosening the hydrogen bonds between water molecules to produce a less rigid structure, the breaking of hydrogen bonds between the two strands of DNA is also called melting. This process can occur through physical means (using proteins and RNA machines) or through increased temperature. In these situations, DNA is always in solution so it does not change what is observed at the macroscopic scale, but the actions at the molecular level are consistent (such as breaking of hydrogen bonds in DNA or water). The process of DNA strands bonding through proper hydrogen bonding interactions is called annealing (not freezing as would be analogous to melting for true phase changes).
 In fact, the use of temperature to control DNA structure is core to the Nobel prize winning development of Polymerase Chain Reaction (PCR). PCR is a mechanism to create many copies of one region of DNA accurately and efficiently. This process can be used to create sufficient quantities of DNA to be visualized in a DNA gel with the naked eye in under 3 hours! This technology is often used for genetic screens, paternity tests, and forensic analysis of DNA, along with other applications in the lab.
In fact, the use of temperature to control DNA structure is core to the Nobel prize winning development of Polymerase Chain Reaction (PCR). PCR is a mechanism to create many copies of one region of DNA accurately and efficiently. This process can be used to create sufficient quantities of DNA to be visualized in a DNA gel with the naked eye in under 3 hours! This technology is often used for genetic screens, paternity tests, and forensic analysis of DNA, along with other applications in the lab.
DNA in our Foods
As mentioned above, DNA is in almost all cells (red blood cells are the notable exception here). In fact, people often purify DNA from fruit, obtaining visible quantities of a stringy white substance (DNA) from just a single strawberry! The common procedure involves forming lots of ionic interactions between ionizable sites along the DNA and salt ions in solutions, followed by precipitation using cold isopropyl alcohol.



")




